









لماذا لا يستطيع الروبوتات النقر على مربع "أنا لست روبوتًا" في المواقع؟

أصبح من المعتاد في عالم الإنترنت رؤية مربعات التحقق التي تطلب منا التأكيد على أننا لسنا روبوتات. هذه المربعات، التي تحتوي على عبارة "أنا لست روبوتًا"، هي جزء من نظام يسمى reCAPTCHA، والذي يهدف إلى حماية المواقع من الأنشطة غير المرغوب فيها. يعتمد نظام reCAPTCHA على عدة تقنيات معقدة للتأكد من هوية المستخدمين وما إذا كانوا بشراً أم روبوتات. ولكن يبقى السؤال: لماذا لا يستطيع الروبوتات ببساطة النقر على هذا المربع والمرور دون مشاكل؟ في هذا المقال، سنستعرض الأسباب التقنية وراء هذا الأمر وكيفية عمل هذه الأنظمة بطرق تحمي المواقع وتضمن أمان المستخدمين. سنستكشف تطور نظام التحقق CAPTCHA، وكيفية عمل reCAPTCHA، بالإضافة إلى الأساليب المخفية التي يستخدمها النظام لتحليل سلوك المستخدمين. كما سنتناول التحديات التي تواجه هذه الأنظمة في المستقبل مع تطور الذكاء الاصطناعي وزيادة قدرات الروبوتات على تنفيذ المهام المعقدة. الهدف هو تقديم فهم شامل لكيفية عمل هذه الأنظمة وأهميتها في الحفاظ على أمان الإنترنت.
قراءة مقترحة
تطور نظام التحقق CAPTCHA
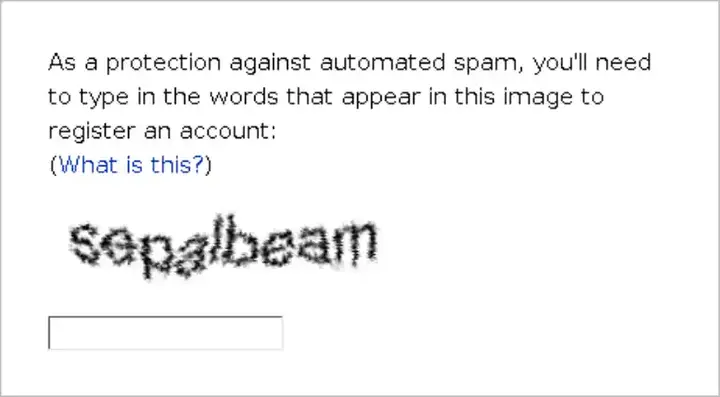
انتقل CAPTCHA من اختبار قراءة النصوص المشوشة إلى نموذج reCAPTCHA الذي يركز على تحليل السلوك، لأن تطور الذكاء الاصطناعي جعل الاختبارات القديمة أسهل على الروبوتات.
محطات التحول من النصوص المشوشة إلى التحليل السلوكي
النصوص المشوشة
اعتمدت الاختبارات الأولى على كلمات أو أحرف يصعب على الروبوتات قراءتها.
تقدم الذكاء الاصطناعي
أصبحت الروبوتات أكثر قدرة على اجتياز اختبارات النصوص، ما فرض الحاجة إلى تحقق أكثر تعقيدًا.
reCAPTCHA السلوكي
أضافت جوجل طبقة تعتمد على سرعة النقر، ومسار حركة الماوس، وتوقيت التفاعل لمواكبة قدرات الروبوتات.
كيف يعمل نظام reCAPTCHA؟
لا يكتفي reCAPTCHA بسؤال المستخدم عن النقر؛ بل يقرأ الطريقة التي حدث بها النقر، ثم يقرر هل يحتاج إلى اختبار إضافي مثل التعرف على الصور.
مسار التمييز بين نقرة بشرية ونقرة روبوتية
مراقبة طريقة النقر
يفحص النظام سرعة النقر ومسار حركة الماوس بدل الاعتماد على وصول المستخدم إلى المربع فقط.
قراءة نمط الحركة
يميل البشر إلى البطء والعشوائية، بينما تكون الروبوتات غالبًا أسرع وأكثر مباشرة وكفاءة.
طلب اختبار إضافي عند الشك
إذا بدا النقر سريعًا جدًا ومباشرًا، قد يطلب النظام التعرف على صور معينة لصعوبة هذه المهمة على الروبوتات.
الأساليب المخفية والمراقبة الشاملة
تستخدم بعض المواقع تحققًا غير مرئي يمنح المستخدمين درجات اعتمادًا على إشارات سلوكية وبيانات متاحة، بهدف الحفاظ على تجربة سلسة وآمنة مع تقليل الاختبارات الظاهرة.
إشارات المراقبة التي تبني تقدير الهوية
يعتمد reCAPTCHA Enterprise والأنظمة المشابهة على دمج عدة عوامل في الوقت الفعلي لتقدير ما إذا كان المستخدم حقيقيًا أم روبوتًا.
مسار الماوس
تُفحص حركة المؤشر وطريقة التنقل لأنها تكشف الفرق بين الحركة البشرية العشوائية والحركة الآلية الدقيقة.
تاريخ التصفح والكوكيز
تساعد البيانات المتاحة مثل سجل التصفح والكوكيز في بناء درجة تحدد احتمال أن يكون المستخدم بشرًا.
التفاعل في الوقت الفعلي
يمكن تحليل التنقل بين الصفحات، والتفاعل مع المحتوى، وحتى سرعة الكتابة لتقديم تقديرات دقيقة لهوية المستخدم.
مستقبل أنظمة التحقق وتحدياتها
مع استمرار تطور الذكاء الاصطناعي، أصبحت بعض الروبوتات قادرة على اجتياز اختبارات تورينغ المعقدة، مما يخلق تحديات كبيرة لأنظمة التحقق الحالية. هذا التطور يفرض على الشركات المطورة مثل جوجل أن تبتكر حلولاً أكثر تعقيدًا وفعالية في التمييز بين البشر والروبوتات. على سبيل المثال، قد نحتاج إلى أنظمة تحقق تعتمد على التحليل العميق للسلوك البشري بطرق أكثر تعقيدًا، مثل تحليل نمط الكتابة، واستخدام الذكاء الاصطناعي لفهم السياق الذي يتم فيه التفاعل مع المواقع. هذه التطورات يمكن أن تشمل استخدام التعلم العميق والشبكات العصبية لتحليل البيانات في الوقت الفعلي وتقديم تقييمات دقيقة لهوية المستخدم. بالإضافة إلى ذلك، يمكن أن تتضمن الحلول المستقبلية تكنولوجيا التعرف على الوجوه أو حتى تحليل البصمات الحيوية كوسيلة إضافية للتحقق من الهوية. ولكن مع كل هذه التطورات، يأتي أيضًا تحدي الحفاظ على خصوصية المستخدمين وضمان أن البيانات الشخصية لا تُستخدم بطرق غير أخلاقية. لذلك، يجب أن تكون هناك موازنة دقيقة بين الأمان والخصوصية، مما يتطلب تعاونًا مستمرًا بين مطوري التكنولوجيا والمشرعين لضمان تحقيق أفضل النتائج. في النهاية، تبقى أنظمة التحقق عنصراً أساسياً في الحفاظ على أمان الإنترنت، ولكن يجب أن تظل مرنة ومتطورة لمواجهة التحديات المستقبلية.
في النهاية، ليس هناك سبب سحري يمنع الروبوتات من النقر على مربع "أنا لست روبوتًا"، بل يتعلق الأمر بكيفية القيام بالنقر. الأنظمة الحالية تعتمد على تحليل السلوك البشري العشوائي والبطيء مقارنةً بالسلوك الروبوتي السريع والدقيق. مع تطور الذكاء الاصطناعي، سنحتاج دائمًا إلى تحديث أنظمة التحقق لضمان الأمان على الإنترنت.